Open datasets block is the primary way to introduce structured, tabular data into your workflow. It allows you to create or import one or more datasets. The workflow then iterates through a combined set of all enabled datasets, making the data from each row available as variables to subsequent blocks.
This block acts as a powerful starting point, enabling you to run the same workflow logic across many different inputs.
Purpose
Use theOpen datasets block to:
- Run a workflow for a list of items (e.g., company names, product URLs, search keywords).
- Import data from a CSV file to be processed.
- Manage multiple distinct sets of input data within a single workflow block.
- Provide the variables needed for dynamic automation in subsequent steps.
Configuration
The main configuration panel for theOpen datasets block shows a list of available datasets for the workflow.
- Dataset List View:
- ENABLED: A checkbox to include or exclude a specific dataset from the workflow run. The workflow will only process rows from datasets that are enabled.
- DATASET NAME: The name of the dataset. By default, the first one is named “Default”. You can rename it. Clicking on the dataset name (e.g., on “Default”) opens the full-screen data table editor for that dataset.
- ROWS: Shows the number of data rows in that dataset.
- + Add Dataset Button: Click this to create a new, empty dataset in the list.
- Data Table Editor (Full-screen view):
- After clicking a dataset name, a full-screen table editor opens. This is where you manage the data for that specific dataset.
- Columns as Variable Names: Each column header you define becomes a variable name (e.g.,
URL,company_name,search_keyword). Remember, these names are case-sensitive. - Rows as Value Sets: Each row in the table represents a distinct set of values for these variables.
- Import Button: Use this to upload data from a CSV file into the current dataset. The first row of your CSV will be used as the column headers (variable names).
- Clone Button: Creates a duplicate of the current dataset.
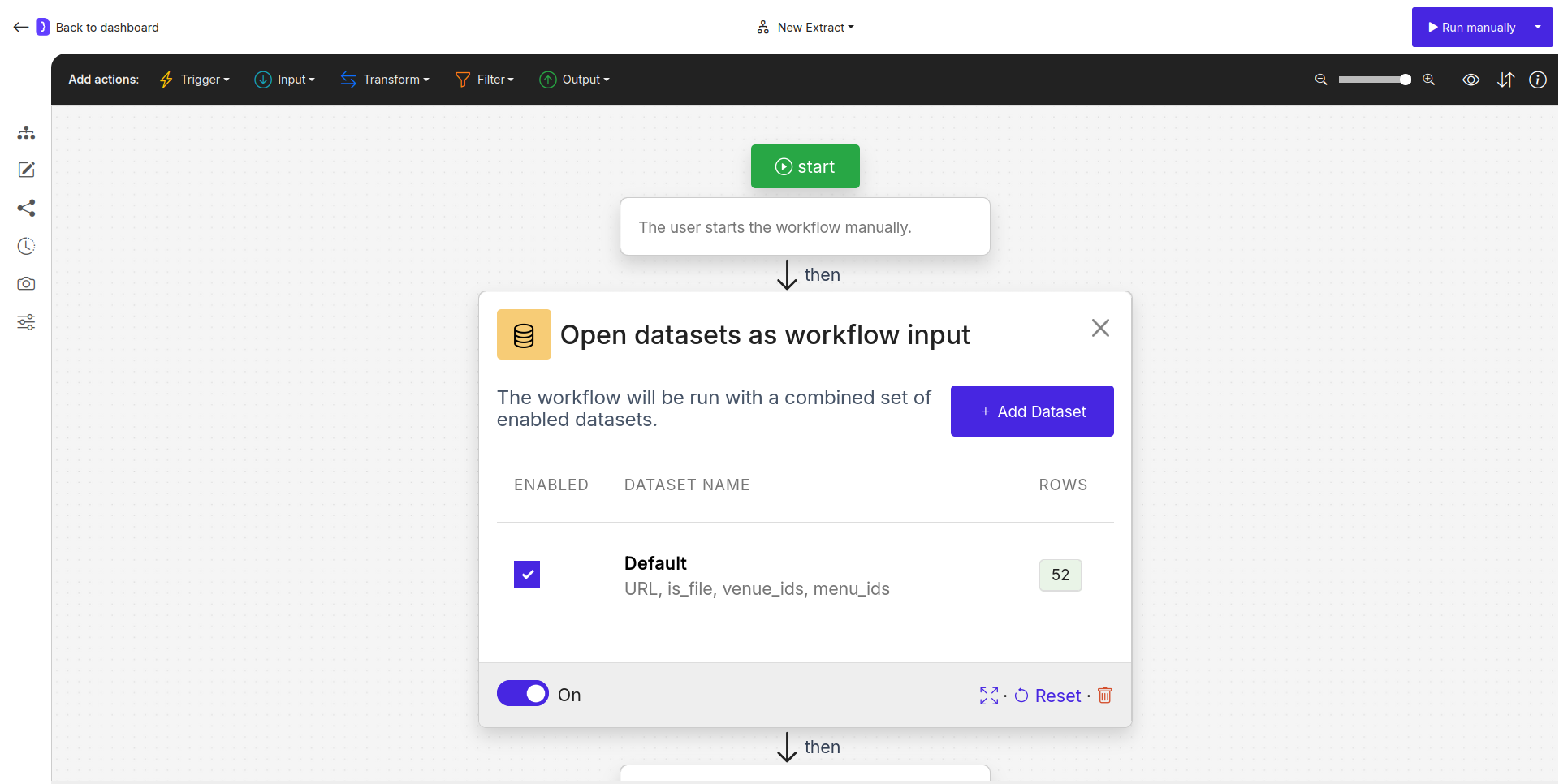
Screenshot: Open datasets block configuration showing a list with one 'Default' dataset
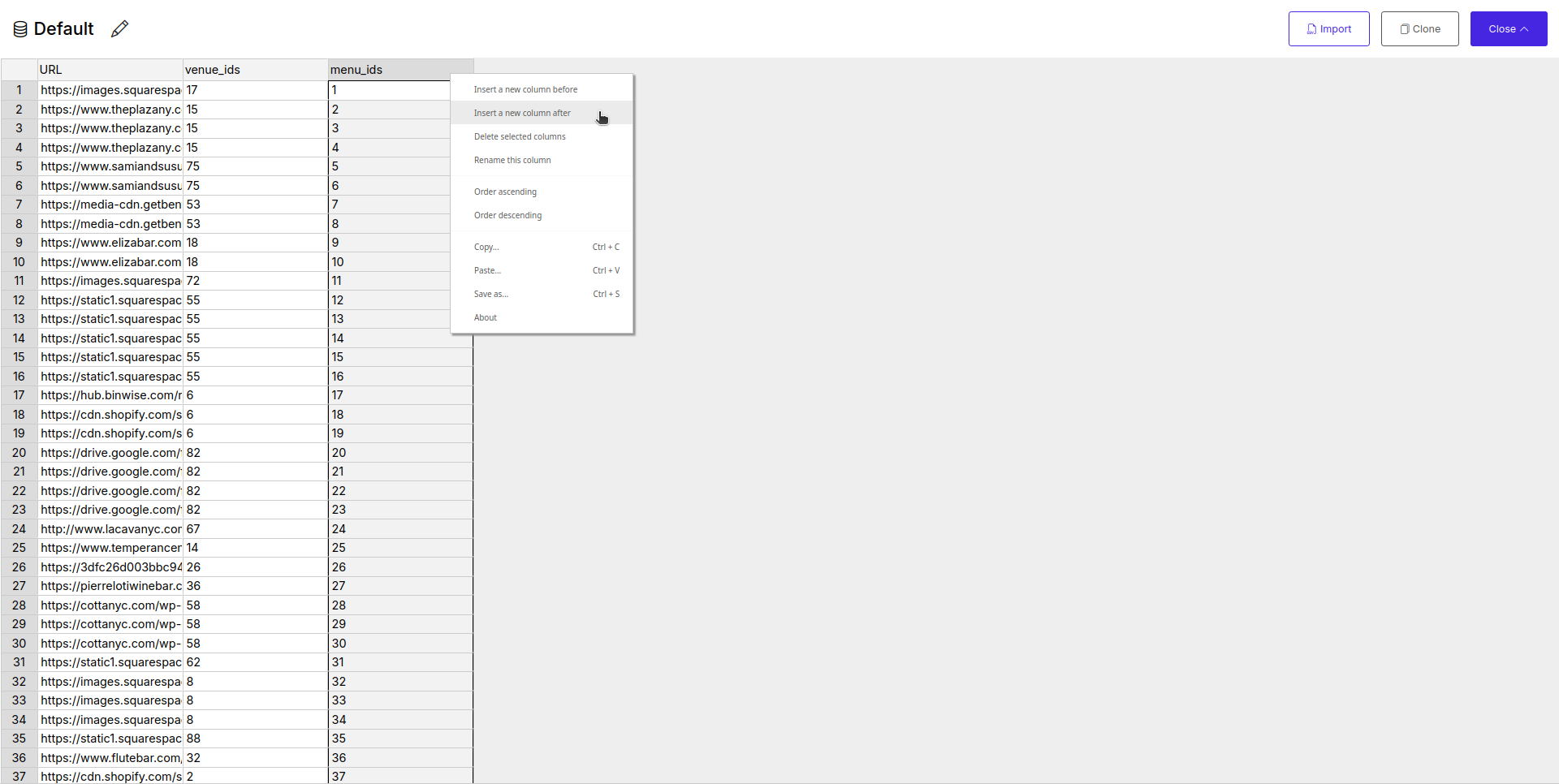
Screenshot: Full-screen data table editor showing columns and rows of data
How It Works
- You define one or more datasets within the
Open datasetsblock. - You enable the datasets you wish to use for the run.
- When the workflow runs, it combines all the rows from all enabled datasets into a single master list.
- The workflow then iterates through each row of this combined list. For each row, the values are assigned to variables (e.g.,
{{URL}},{{company_name}}), and the subsequent blocks are executed using these variables.
Special Column Name: URL
If you name a column exactly URL (case-sensitive) and provide valid, complete URLs (starting with http:// or https://) in its rows, the AI Agent will automatically open each of these URLs. In this specific case, a subsequent Open Websites block is not required to open these particular URLs.
Example: Processing URLs from Two Datasets
Open datasets Block:- Dataset 1 (“Competitors”): Enabled. Contains a
URLcolumn with links to competitor websites. - Dataset 2 (“Partners”): Enabled. Also contains a
URLcolumn with links to partner websites. - Dataset 3 (“Old_Data”): Disabled. Contains old URLs that should not be processed.
- Dataset 1 (“Competitors”): Enabled. Contains a
Extract Data Block (added next):- Configured to extract the
<title>tag from each page.
- Configured to extract the
- Result: The workflow will first process all URLs from the “Competitors” dataset, then all URLs from the “Partners” dataset. The
Extract Datablock will run for each URL from both enabled datasets, and the results will show the page titles for all of them. The “Old_Data” dataset will be ignored.
Key Considerations
- Variable Names are Case-Sensitive:
{{url}}is different from{{URL}}. Ensure consistency. - Combined Datasets: The workflow processes a combined list from all enabled datasets. The order of processing usually follows the order of datasets in the list and the order of rows within each dataset.
- Primary Data Source: This block is a fundamental data source. It initiates the iterative execution of the workflow for each row of data it provides.
Open datasets block is your central hub for managing and inputting tabular data to drive powerful, scalable, and reusable automations in Jsonify.