Goal
To scrape theitem_name and sugar_grams from the menu category pages of McDonald’s and Wendy’s. The key challenge is that each site requires a different automation approach:
- McDonald’s (Standard Site): We will find all product links, follow them, and then click a spoiler to reveal nutritional information.
- Wendy’s (JavaScript Site): We will use the
Open sub-pagesblock to navigate the menu, as direct links might not be available.
Key Blocks Used
Open datasets(Input)Layoutmenu (Add new row,Link actions)Find Links(Transform)Follow Links(Input)Open sub-pages(Transform)Interact with Page(Transform)Extract Data(Transform)
What You’ll Learn
- How to structure your input data to handle different automation scenarios.
- How to use the Layout menu to create parallel execution branches.
- How to build different automation logics for different types of websites.
- How to link and merge the results from parallel branches into a single, unified
Extract Datablock.
Steps
1. Prepare Your Input Data
The key is to prepare your data to guide each branch.- Create a new workflow and start with an
Open datasetsblock. - Inside the dataset, create two columns:
URLandcontain. - The
URLcolumn will hold the links to the menu category pages. - The
containcolumn will hold a text snippet that is unique to the product links on that site, which helps theFind Linksblock.
2. Build the First Row (McDonald’s - Standard Navigation)
This branch will handle the McDonald’s links.- Start with an
Open datasetsblock containing the data from the table after.
- Add a
Find Linksblock. Configure it with a dynamic goal:Find all links to each product's page that must contain '{{contain}}'. This uses the variable from our dataset. - Add a
Follow Linksblock next. Configure it toFollow each linkfound by the previous step. - Add an
Interact with Pageblock to click the spoiler. Configure it with the action:Click on "Nutritional Information".
3. Add a Parallel Row
Now we’ll create the separate branch for Wendy’s.- Click on the
Layoutmenu in the top action bar. - Select
Add new row. A new “start” placeholder will appear on your canvas. AddOpen datasetsblock from the top menu.
4. Build the Second Row (Wendy’s - JavaScript Navigation)
- Select the new
Open datasetsblock. It will use the same data as the first one.
- Add an
Open sub-pagesblock after it. This block will handle the JavaScript-driven menu.- What pages do you want to open?:
open each menu item on the page - How many pages to extract?: Set a reasonable limit, e.g.,
20.
- What pages do you want to open?:
5. Link and Merge the Branches
Now, we will direct the output of both branches into a single, finalExtract Data block. This block will have the final context from whichever branch was active for a given input row.
- Click on the
Layoutmenu and selectLink actions. - Click on the
Open sub-pagesblock (the last block of Row 2), then click on theExtract Datablock, it’s at the end of the first brunch. Now, second branch feed into it.
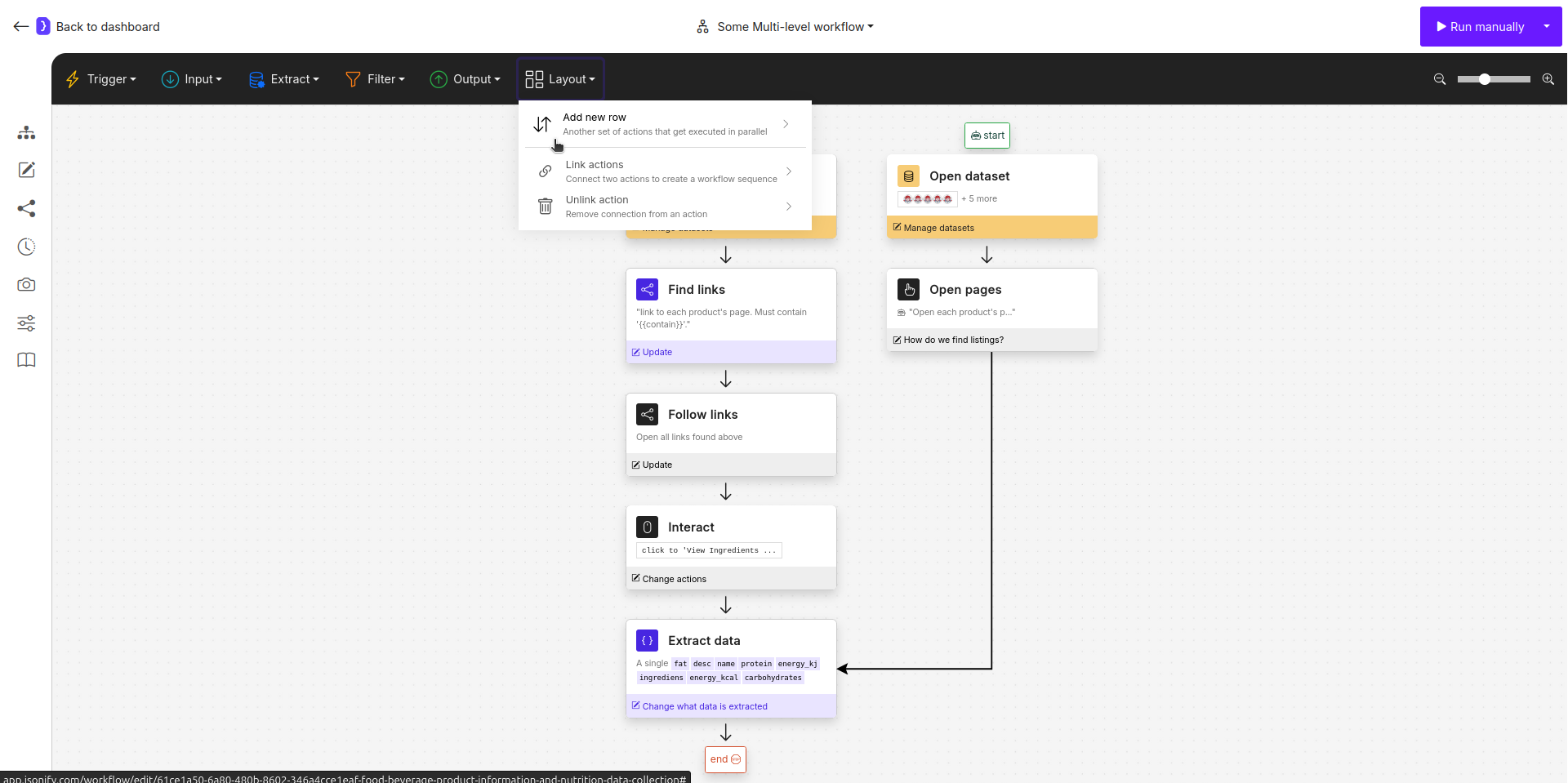
Screenshot: A multi-level workflow showing two parallel rows being linked into a single, final Extract Data block
6. Configure the Final Extract Data Block
This block will now receive the final product page from either of the two branches.
- Select the final
Extract Datablock. - What information…?: Choose
A single item. - Attributes: Define a single, unified schema that works for both McDonald’s and Wendy’s product pages.
7. Run and Check Results
- Run the workflow. The agent will process each row from your dataset. It will intelligently choose the correct path based on which blocks can execute.
- The final output will be a single, clean list of menu item names and their sugar content, collected from both websites.