Goal
To collect detailed information for multiple movies listed on a website. This involves:- Opening an initial movie listing page.
- Finding links to individual movie detail pages.
- Navigating to each movie detail page.
- Extracting structured data (e.g., title, rating, synopsis, director, cast) from each detail page.
Key Blocks Used
Open WebsitesFind LinksFollow LinksExtract Data
What You’ll Learn
- How to navigate from a general listing/category page to multiple individual detail pages.
- How to use
Find Linksto identify specific URLs andFollow Linksto visit them. - How to set up an
Extract Dataschema for information found on detail pages. - A common pattern for “deep dive” data collection.
Steps
1. Create a New Workflow
- Navigate to your Jsonify Dashboard.
- Click the button sequence to create a new workflow: Create an empty workflow ➙ Extract.
- This template will already include
Open WebsitesandExtract Data. We will addFind LinksandFollow Linksmanually.
- This template will already include
2. Configure Open Websites Block
- Select the
Open Websitesblock. - For this tutorial, we’ll use a Rotten Tomatoes page listing movies in theaters as an example. In the URL input field, add:
https://www.rottentomatoes.com/browse/movies_in_theaters
- Ensure the toggle switch next to the URL is ON.
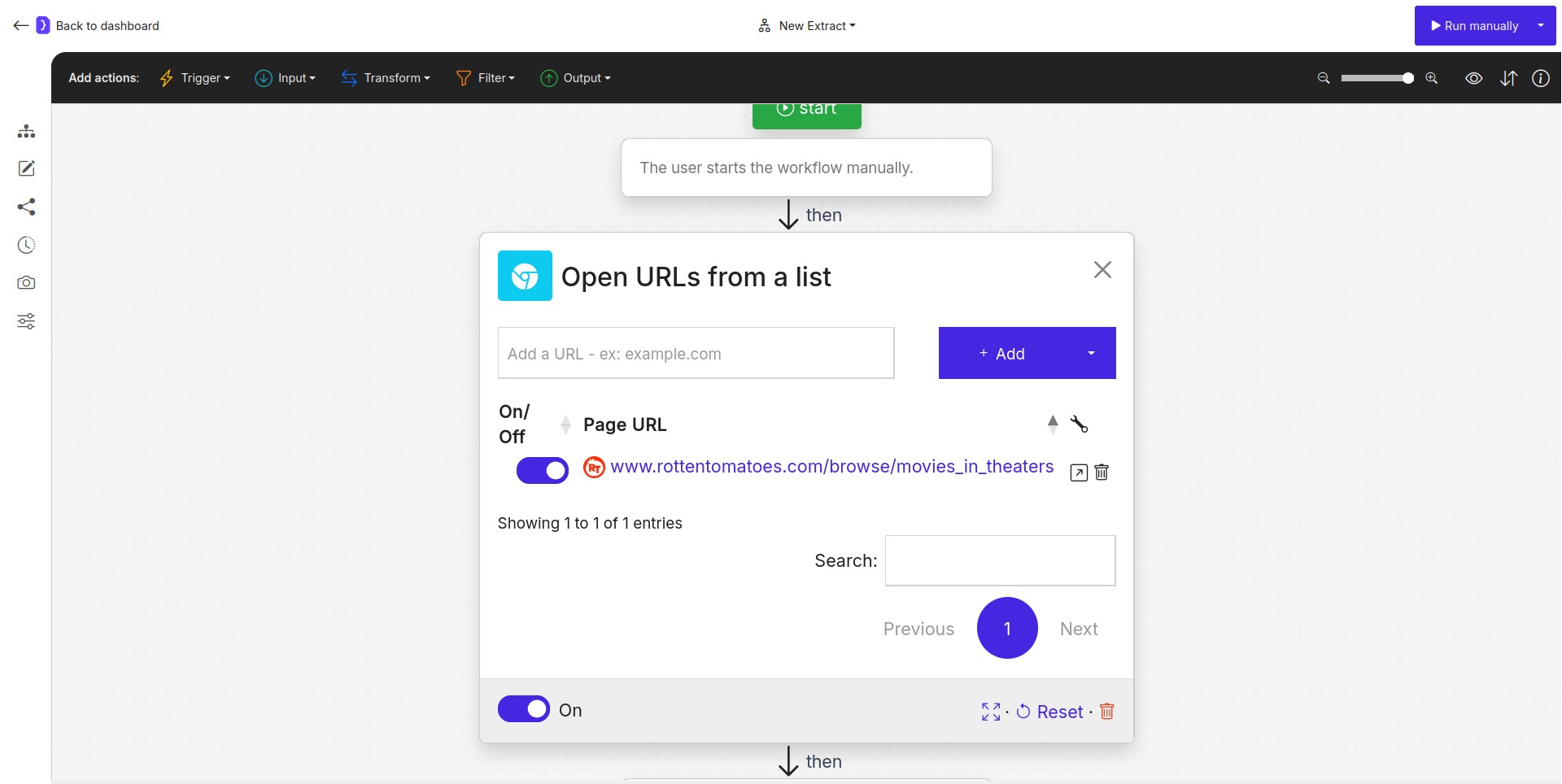
Screenshot: Open Websites block configured with Rotten Tomatoes URL
3. Add and Configure Find Links Block
- After opening the listing page, we need to find the links to individual movie pages.
- To add a new block:
- Look at the block categories at the top of the editor (e.g., Trigger, Input, Transform, Filter, Output).
- Select the Transform category.
- From the dropdown list of blocks that appears, select
Find Links. - Now, click the
+icon on the canvas at the point where you want to add the block (i.e., after theOpen Websitesblock). TheFind Linksblock will be added and connected.
- Select the
Find Linksblock to configure it.- What kind of links?: Enter a description like
Find links to individual movie pages in the main list. You might add constraints likeLinks must contain '/m/'if you observe a pattern in Rotten Tomatoes movie URLs.
- What kind of links?: Enter a description like
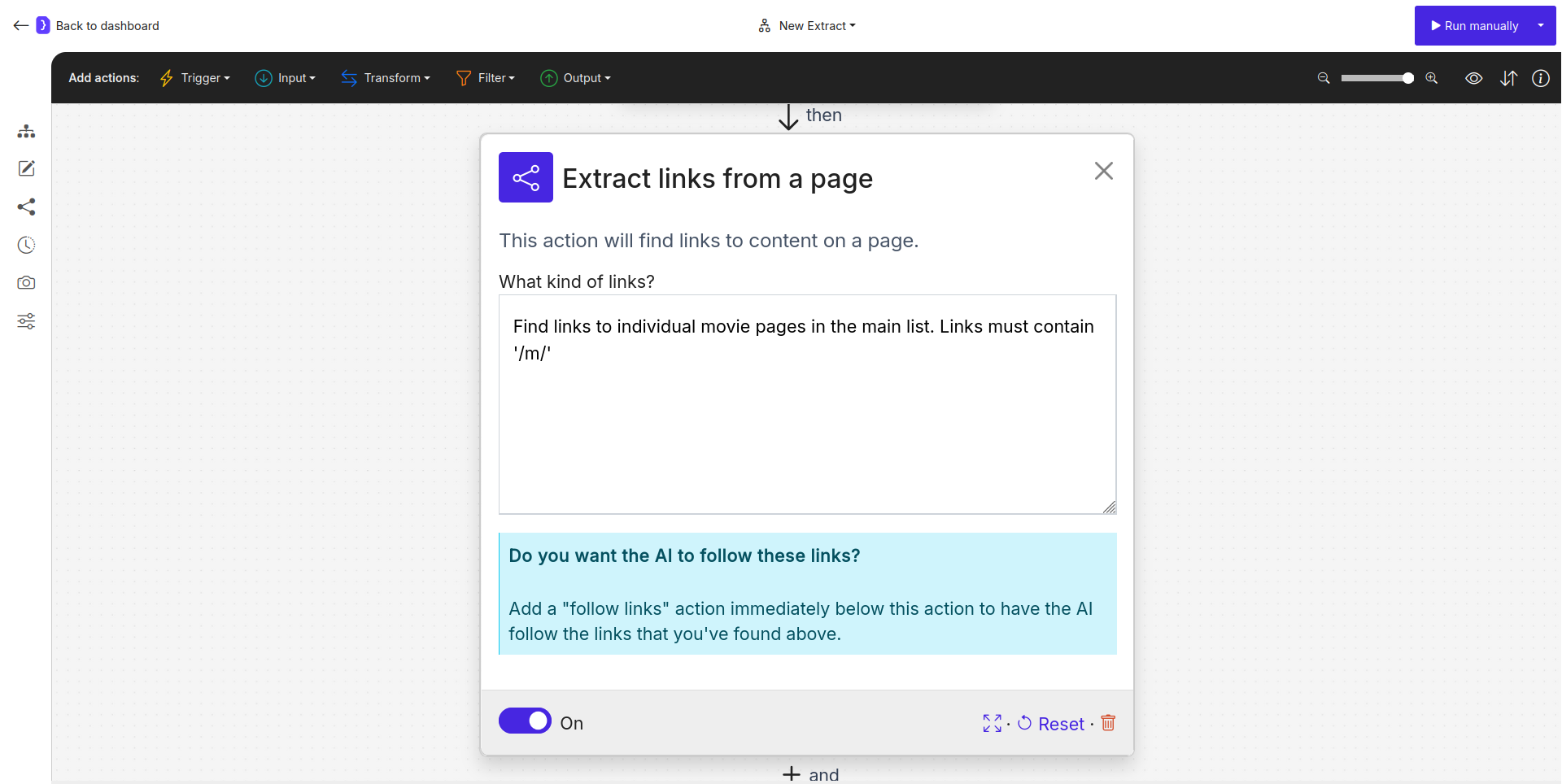
Screenshot: Find Links block configured to find movie page links
4. Add and Configure Follow Links Block
- Once the links are found, the agent needs to visit each one.
- To add a new block:
- Look at the block categories at the top of the editor.
- Select the Input category.
- From the dropdown list, select
Follow Links. - Click the + icon on the canvas after the
Find Linksblock. TheFollow Linksblock will be added and connected.
- Select the
Follow Linksblock to configure it.- Which links to follow?: Choose
Follow each link. This will make the subsequentExtract Datablock run for every movie page found.
- Which links to follow?: Choose
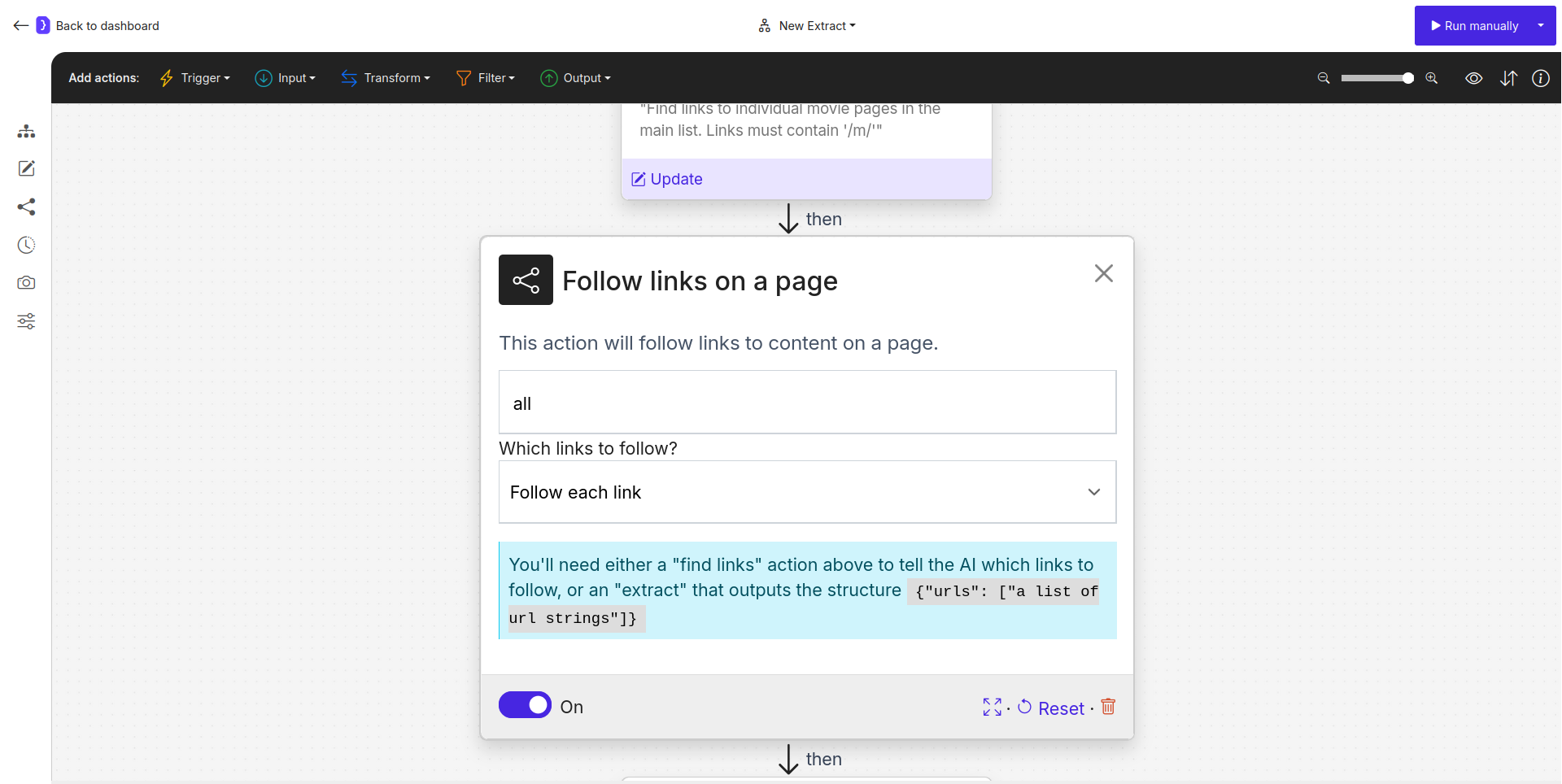
Screenshot: Follow Links block configured to 'Follow each link'
5. Configure Extract Data Block
-
This block will now execute on each individual movie page that the
Follow Linksblock navigates to. -
Select the
Extract Datablock (it should be afterFollow Links). -
What information should we scrape from each URL?: Select
A single item, as each movie page contains details for one movie. -
Define the attributes (fields) for each movie:
-
Add additional instructions and guidance…:
You are on a movie detail page. Extract the specified information. If a field is not present, leave it empty.
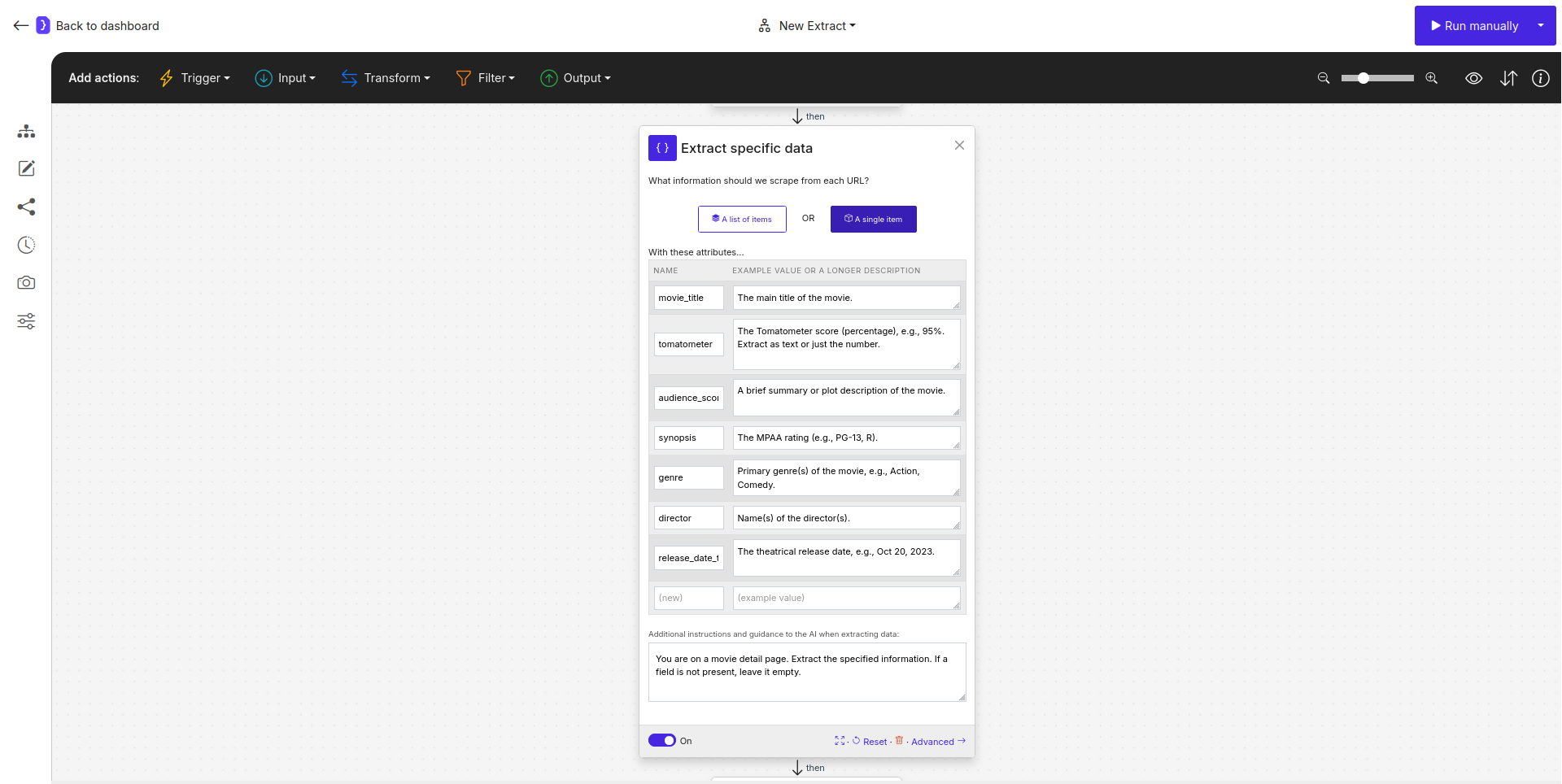
Screenshot: Extract Data block configured for extracting movie details
6. Run Your Workflow
- Click the Run manually button.
- The agent will:
- Open the Rotten Tomatoes movie listing page.
- Find all links to individual movie pages.
- For each movie link found: a. Navigate to the movie’s detail page. b. Extract the defined information (title, scores, synopsis, etc.).
7. Check the Results
- You will be redirected to the current run’s page where results will populate.
- Once completed, click on “View as sheet”.
- You should see a table where each row represents a movie, and the columns contain the details you specified for extraction.