Merge data block functions similarly to the Extract Data block, but its exclusive purpose is to merge existing data into a new, unified format. It does not extract new information from a webpage. Instead, it collects variables that are already available in the workflow’s context (from previous Open datasets, Extract Data, or other blocks) and structures them into a final output.
This block is essential for consolidating data from various sources into a clean, final schema before the workflow ends.
Purpose
Use theMerge data block to:
- Create a final, clean data structure at the end of a workflow.
- Merge data from an initial input (e.g., an
idfrom anOpen datasetsblock) with data extracted from a webpage (e.g., atitlefrom anExtract Datablock). - Combine results from multiple, separate
Extract Datablocks into a single, cohesive output. - Select only the necessary fields from a larger set of available variables for the final result.
Configuration
- What information should we combine?
- This choice determines the structure of your final output.
- A list of items: Use this if you are processing a list and want each merged item to be a separate row in the final results.
- A single item: Use this if you are combining data for a single entity into one result row.
- Defining Attributes (The Data Table):
- You will define the structure of your final output in a table-like interface.
- NAME (Column 1): This is the name of the variable you want to include in the final output. The agent will look for an existing variable with this exact, case-sensitive name in the data available from all preceding steps.
- EXAMPLE VALUE (Column 2): This field is typically left empty, as the block uses existing data. However, you can use it to provide notes or examples for clarity if needed. The primary mechanism is matching the
NAMEto an existing variable.
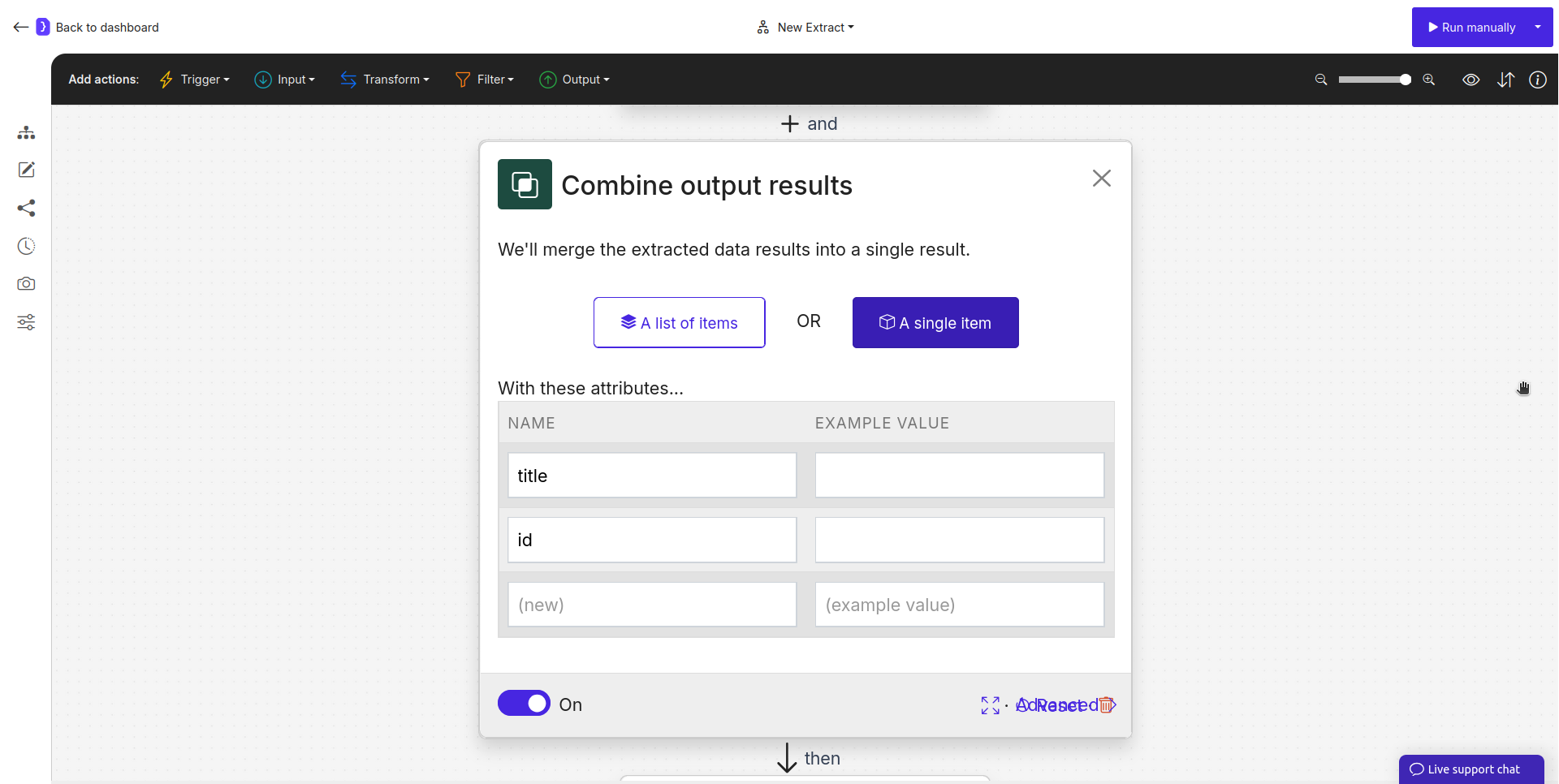
Screenshot: Merge data block configuration panel showing the item type selection and attributes table with 'title' and 'id'
How It Works
- Place the
Merge datablock at a point in your workflow where all the data you want to merge is available. This is often at the end of an iteration loop or as the final step of the entire workflow. - Define the desired output schema by listing the
NAMEof each variable you want to include. - When the workflow runs, this block gathers the values of the variables from the preceding steps that match the names you’ve listed.
- It then creates a new, single result (or a list of results) containing only the fields you specified, effectively merging them into one clean structure.
Example: Merging Input Data with Extracted Data
Imagine a workflow that starts with a dataset of products, each with aURL and a unique id. The goal is to visit each URL, extract the product’s title, and then combine the original id with the newly extracted title.
Open datasets Block:- Contains two columns:
URL(e.g.,https://example.com/product/123) andid(e.g.,123).
- Contains two columns:
Extract Data Block (added next):- This block runs on each URL from the dataset.
- It is configured to extract one attribute:
- NAME:
title, DESCRIPTION:The main title of the product.
- NAME:
Merge data Block (added next):-
What information…?:
A single item(since we are creating one final row per product). -
Attributes:
-
What information…?:
- Result: The final output will be a table with two columns, “title” and “id”. For each product, the
titlewill be taken from theExtract Datastep, and theidwill be taken from the initialOpen datasetsstep, perfectly merging them into a single, clean result row.
Key Considerations
- Data Reorganization, Not Extraction: This block’s purpose is to structure and combine existing data, not to extract new data from a source.
- Variable Name Matching: The block relies on exact, case-sensitive matching between the
NAMEyou provide in its table and the names of variables available from previous steps. - Workflow Placement: This block is most effective when placed at the end of a processing sequence to consolidate all gathered information into a final, desired format.
Merge data block is a crucial tool for cleaning and structuring your final data, ensuring you get exactly the output you need from your complex workflows.